I Think My Knee Hurts, I Just Can’t Prove It
Hopefully, you really do know if your knee hurts or not… it’d be odd if you weren’t sure. Regardless, this isn’t about knees but networks and specifically dealing with SQL Server Always On. I’m going to start out by stating that there are many improvements that could be made in this area, however, none of them are trivial. I’m not going to get into specifics as the amount of typing that would require is out of the question, I’m too lazy efficient.
Let’s get to the point, the way that SQL Server Always On works and how it uses your network is not the way you believe it works. I’m sure you’re shocked. In a time in computing when using a billion threads, pipelines, workflows, whatever you want to call it to do basic units of work is just assumed and never tested. I can’t really blame you… when you drag and drop a file using explorer, or robocopy entire recursive directories to another disk, etc., this is all to some point parallelized for you. It gives the notion that you’re going fast, just look at the progress bar zip along the screen! I’m not going to delve into various mechanics or algorithms at play, but rather to explain why you’re seeing what you are when it comes to AGs and networking.
Unionized Labor
SQL Server loves its pools… thread pools, resource pools, etc., and for good reason. When it comes to Availability Groups, though, it’s a mixed bag and there’s sometimes good reasons for doing it one way over another. Always On uses worker pools as well as it operates in a very asynchronous manner, however one place this is not the case is in sending and receiving log streams. You’ll know this as sending and receiving the log blocks and filestream data between database replicas where there is a single thread for each purpose per database replica. How does this play into network throughput hysteria? Glad you asked…
Trivialities
Let’s assume that you’re setting up an Availability Group between two replicas, it’ll only contain one database for now and the workload isn’t very heavy since it’s just starting to be tested. Everyone pats each other on the back that the AG has been setup, everything is working, connectivity is there.
Eventually the database becomes more and more busy as users or services are added and now, we’re starting to really get some traffic… to the point where someone looks at the AG Dashboard in SSMS (because this doesn’t exist in ADS, because ADS wasn’t really made for DBAs [rant over]) and notices that there is a send queue building up. Well, that’s not good, and generally the first things I hear out of people’s mouths (or emails) are, (1) There is a bug in SQL Server, and (2) there is a problem with the network. In almost every situation, (1) is not the case – yes SQL Server like every other piece of software has bugs – but rarely will something so trivial cause one to rear its head (unless your argument is that something is a bug if it doesn’t work the way you personally believe it should). The second is more likely and is sometimes the case, but generally that’s also not the case, but it’s the easiest to point to and say, “AHA!”. This happens… A LOT.
California DMV Efficiency
You’re an extremely talented and gifted DBA, so you pull up the network performance counters and see that the dedicated network SQL Server is setup to use for AG traffic is only using 30 MB/sec… obviously that’s a network issue, time to go give networking a piece of your mind! Not so fast. I almost never see anyone test their network the way that SQL Server uses it for AG traffic, which is as I stated before, a thread per database replica. I like to use ntttcp to do this as you can specify one thread and one core, which is how it’s going to work, unlike the apple to cockatrice comparison done by copying a file across your network.
This is the time everyone gets angry because they stood in line for 9 hours and still didn’t get to the counter. I totally get it, sadly this is the world we live in. Running the ntttcp test might reveal that, in fact, while your network cards are these amazingly great 10Gb cards, using a single core and a single thread you’re only able to get 28 MB/sec max per thread. This assumes you get full use of said core and thread, along with full boxcars, but we’re going to assume for length of explanation reasons that this is the case. This means that if your database has a workload that pushes more than 28 MB/sec in log flushes then you’re going to run into problems. Normally, this is where I get a bunch of gruff about how it should use all these threads and be super-fast and use every possible available nibble of the network interface… much like how the same argument is made for CPU usage with queries – it should just use all cores, on all chips, 100% to just make the query finish faster…. Yeah nah.
Generally, for on-prem, quality hardware (or virtual machines configured properly for performance), this generally isn’t too much of a problem when the servers are close to each other. Latency is low, which means round-trip time is very small and thus the amount of data we can transfer per second is high. However, in the case of longer round-trip times, such as AGs that span thousands of miles, countries, or continents, will be able to send and receive less data per second. Remember that AGs are a high availability and disaster recovery feature, in high availability you wouldn’t want a bunch of outstanding unacknowledged data on the lines just waiting to be lost – that’d do no one any good. In terms of disaster recovery that’s also not a very good idea but is more palatable that in a high availability scenario.
Just for the sake of discussion let’s talk about doing the same thing in your favorite cloud provider. This is basically the single worst thing you can do for AG throughput. If you have a server in one region and a server in another region which you can test (in another country, in another region would be even better!) I’d love to see the results. In possibly one of the worst possible setups for this I’ve witnessed, it was between one cloud provider on one continent with a replica to another cloud provider in another continent halfway around the world. The latency was terrible, just god-awful, that the max throughput (again, everything perfectly maxed out) was 3 MB. You’re not going to do much with that. Now, suddenly, it really is a network problem!
Sometimes You Just Have To Hit a Single
Now that you know the limits, sometimes it’s best to just make sure you’re doing the due diligence. If you’re looking to setup an AG and not sure how well it’s going to work, understanding these basic concepts and configurations will give you a better idea of if things are a good fit based on your infrastructure (or with cloud, lack thereof). Being the person that must step up to the plate and hit the single instead of the homerun isn’t fancy, flashy, or sexy… but you’ll save a lot of people headaches down the line, and that’s being a good team player.
Selfies
Here is an example of two Hyper-V Windows 19 servers setup on my local laptop – which is cheating for various reasons, but the setup that I have (feel free to send me servers and/or money for better testing setups ).
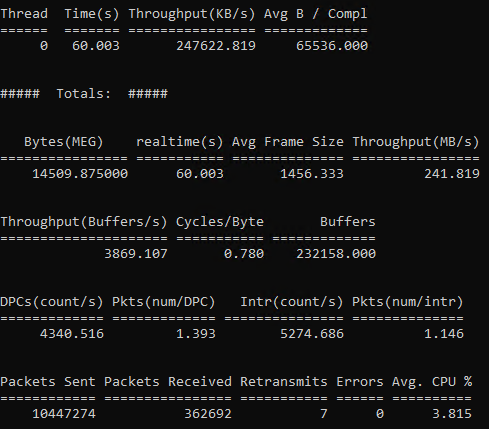 The test run to the left shows that the test was executed over a period of 1 minutes (60 seconds) and was able to push 1 thread and 1 core for a maximum throughput of 241 MB/sec. I stated this was kind of cheating because this stays all internal to my laptop and doesn’t get routed or switched, also since both VMs are local there are some local shared memory efficiencies that take place. In this case if my database had more than 241 MB/sec in log flushes per second, I’d be in some trouble. This isn’t to say you can’t get this setup with a properly setup system. Generally, though, this is contending with all the other things you’re throwing at SQL Server, including all those read queries, all that write traffic, the 3 different monitoring software packages being used, the various antivirus software installs constantly scanning everything, etc., so rarely will you get the true single threaded maximum.
The test run to the left shows that the test was executed over a period of 1 minutes (60 seconds) and was able to push 1 thread and 1 core for a maximum throughput of 241 MB/sec. I stated this was kind of cheating because this stays all internal to my laptop and doesn’t get routed or switched, also since both VMs are local there are some local shared memory efficiencies that take place. In this case if my database had more than 241 MB/sec in log flushes per second, I’d be in some trouble. This isn’t to say you can’t get this setup with a properly setup system. Generally, though, this is contending with all the other things you’re throwing at SQL Server, including all those read queries, all that write traffic, the 3 different monitoring software packages being used, the various antivirus software installs constantly scanning everything, etc., so rarely will you get the true single threaded maximum.
The opposite problem can also happen, where you have so many databases, that it does overload the connection and honestly this happens the most in cloud environments that are geographically dispersed or are between cloud providers… don’t ask. I’d be remiss if I didn’t state that I see disk being an issue way before network for most same region or closely located cloud environments.
I’d love to hear what your values are, if you decide to test this, along with the rough distance between the replicas.
What did you use to run your tests?
Happydba,
I use ntttcp which is available on github: https://github.com/microsoft/ntttcp
You’ll want to limit it to one session and one core as I stated in the article above, for example:
ntttcp.exe -s -p 5000 -t 60 -m 1,0,x.x.x.x=> where x.x.x.x was an IPv4 address of the interface that the receiver will be available.Thank you! Great article!
If I wanted to estimate having, say, 20 databases in AG – would I use 20 threads or cores in ntttcp then?
You’d still run it with one thread as that’s the maximum for a single database for throughput. You’ll have one per database, so long as 20 * throughput <= network throughput then you'd be fine from a *total* network throughput standpoint. You'll still need to check the single network throughput against the log bytes flushed and look at the total log bytes flushed to be <= network throughput.